Enhancing stop location detection for incomplete urban mobility datasets
Abstract
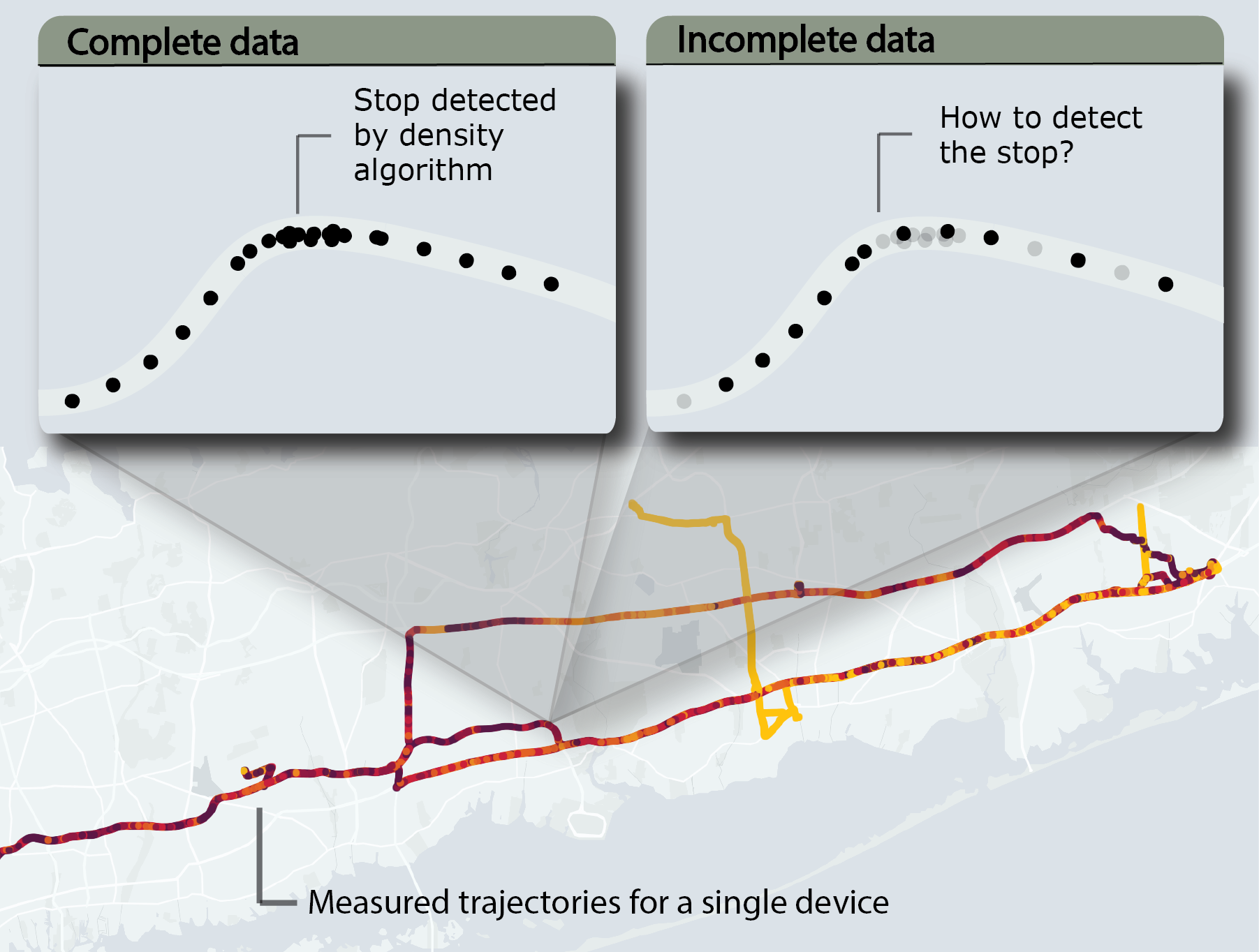
Stop location detection, within human mobility studies, has an impacts in multiple fields including urban planning, transport network design, epidemiological modeling, and socio-economic segregation analysis. However, it remains a challenging task because classical density clustering algorithms often struggle with noisy or incomplete GPS datasets. This study investigates the application of classification algorithms to enhance density-based methods for stop identification. Our approach incorporates multiple features, including individual routine behavior across various time scales and local characteristics of individual GPS points. The dataset comprises privacy-preserving and anonymized GPS points previously labeled as stops by a sequence-oriented, density-dependent algorithm. We simulated data gaps by removing point density from select stops to assess performance under sparse data conditions. The model classifies individual GPS points within trajectories as potential stops or non-stops. Given the highly imbalanced nature of the dataset, we prioritized recall over precision in performance evaluation. Results indicate that this method detects most stops, even in the presence of spatio-temporal gaps and that points classified as false positives often correspond to recurring locations for devices, typically near previous stops. While this research contributes to mobility analysis techniques, significant challenges persist. The lack of ground truth data limits definitive conclusions about the algorithm’s accuracy. Further research is needed to validate the method across diverse datasets and to incorporate collective behavior inputs.